Last Updated on 4 Jahren ago by TmoWizard
Werte Leserinnen und Leser,
 eine Suchmaschine ohne Index bringt bekanntlich nichts! Es ist ziemlich einleuchtend, daß das bedingt natürlich auch für YaCy gilt. Aus diesem Grund zeige ich euch heute zwei Möglichkeiten, wie man YaCy mit Wissen befüllt. Dabei ist es egal, wie und wo ihr YaCy installiert habt. Die Suchmaschine kann wie bei mir auf einem extra Server laufen oder auch im Hintergrund auf einem normalen Arbeitsrechner, wobei die letztere Methode einen großen Fehler hat!
eine Suchmaschine ohne Index bringt bekanntlich nichts! Es ist ziemlich einleuchtend, daß das bedingt natürlich auch für YaCy gilt. Aus diesem Grund zeige ich euch heute zwei Möglichkeiten, wie man YaCy mit Wissen befüllt. Dabei ist es egal, wie und wo ihr YaCy installiert habt. Die Suchmaschine kann wie bei mir auf einem extra Server laufen oder auch im Hintergrund auf einem normalen Arbeitsrechner, wobei die letztere Methode einen großen Fehler hat!
Der Index von YaCy
Zum Zeitpunkt meines letzten Tutorials mußte ich aus technischen Gründen mein System neu einrichten, mein Index ist deswegen noch ziemlich klein:

Das wollen wir heute ändern, wobei ein Senior – oder Principal Peer wie in meinem Fall seinen Index ja mit anderen Peers austauscht und dieser dadurch automatisch größer wird. Sehr langsam zwar, aber es wird. Die Größe eines Index ist dabei alleine Abhängig von der Größe eurer Festplatte, zu gering sollte diese nicht sein! Meine 320 GB dürften wohl bald am Limit sein, aber meine große Festplatte (2 TB) hat sich ja leider vor kurzer Zeit verabschiedet.😱
Der Crawler
Der übliche Weg um eine Website zu indexieren ist natürlich der Crawler, das macht jede Suchmaschine so. In der Administration von YaCy gibt es dafür das „Produktionsmenü“ links in der Sidebar:
Hier klicken wir nun auf den Punkt „Experten Crawl Start“, damit kommen wir zu diesem Bild (Teil 1):
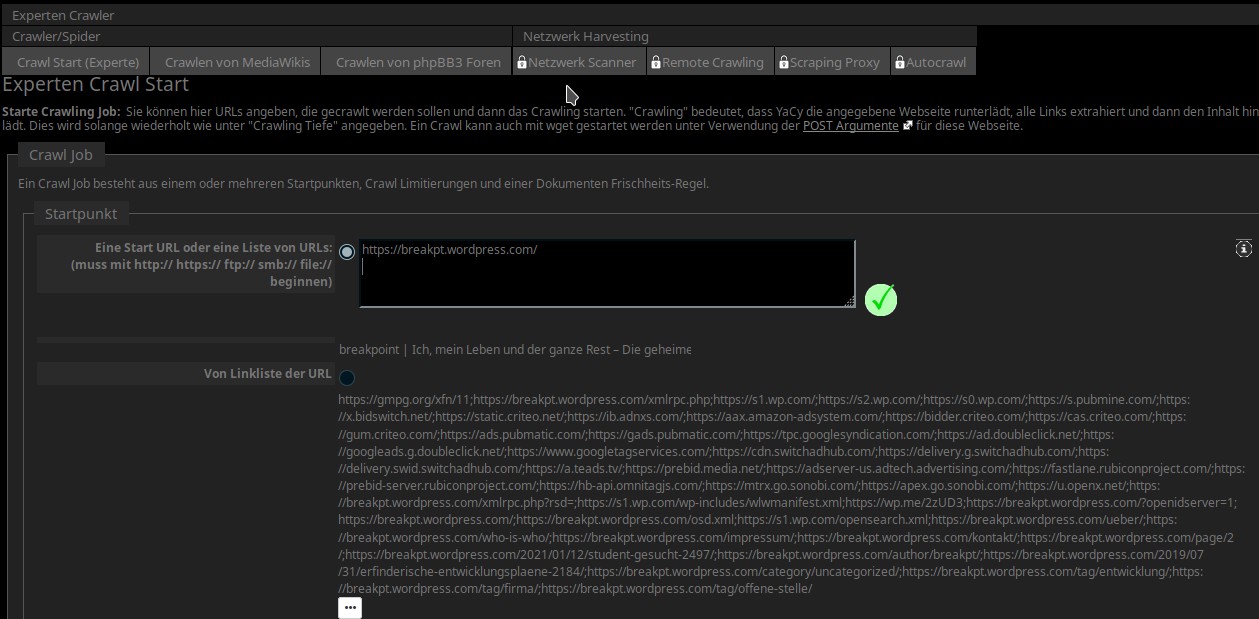
Man gibt hier also die URL einer Website ein und drückt die „ENTER“- oder „Return“-Taste, dann kann noch eine (oder auch mehrere) weitere Seite angeben. Wie schon im letzten Tutorial muß ich auch hier mehrere Screenshots machen, hier also Teil 2:
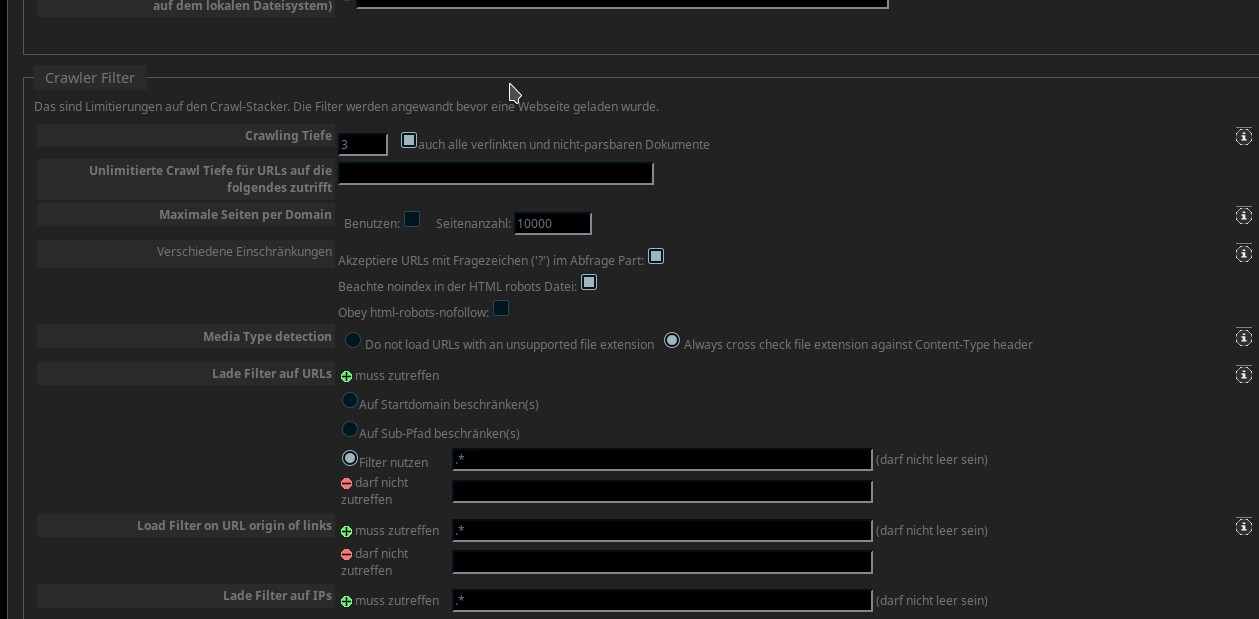
Nicht erschrecken über die vielen Punkte, für uns ist nur die „Crawling Tiefe“ wichtig. Wenn ihr mit eurem Rechner noch andere Dinge erledigen wollt, dann solltet ihr die 3 hier stehen lassen! Viel höher würde ich nicht gehen, denn ja nach Größe der Website und den dort verwendeten Links zu anderen Seiten kann das ziemlich lange brauchen. Dazu eine kurze Erklärung:
Die Suchtiefe
Ein Beispiel:
Beim Crawl meines Castle hier wäre das die Suchtiefe 0, Links werden dabei nicht beachtet! Die Suchtiefe 1 würde dann den vorhandenen Links zur nächsten Seite folgen bzw. bei mehreren Links eben auch zu diesen Seiten. Das gilt natürlich für alle Artikel auf meinem Castle, es sind also in meinem Fall viele Links. Dazu ein entsprechendes Bild zur Erklärung:
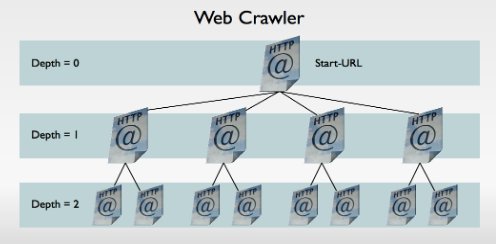
Je tiefer also die Suche geht, desto mehr Seiten werden damit in die Suche einbezogen. Wenn eine Website also viele Links zu verschiedenen Seiten verwendet und diese ebenfalls viele Links hat, dann geht das gehörig auf die Rechenleistung eures Peer und dauert natürlich auch entsprechend lang! Mein voriges System hat für mein Castle bei einer Suchtiefe von 6 über eine Woche gebraucht, das sollte man also nicht unbedingt nachmachen.😵
Man benötigt hier also keine weiteren Einstellungen, sondern klickt ganz unten auf den Button „Neuen Crawl Job starten“ und YaCy legt los!
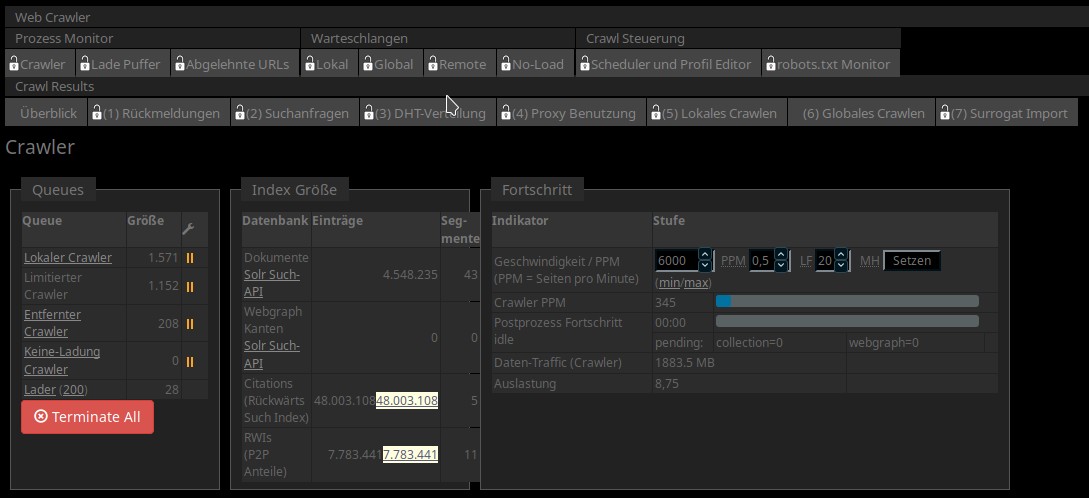
YaCy leitet euch dann automatisch zur „Crawler Überwachung“ weiter:
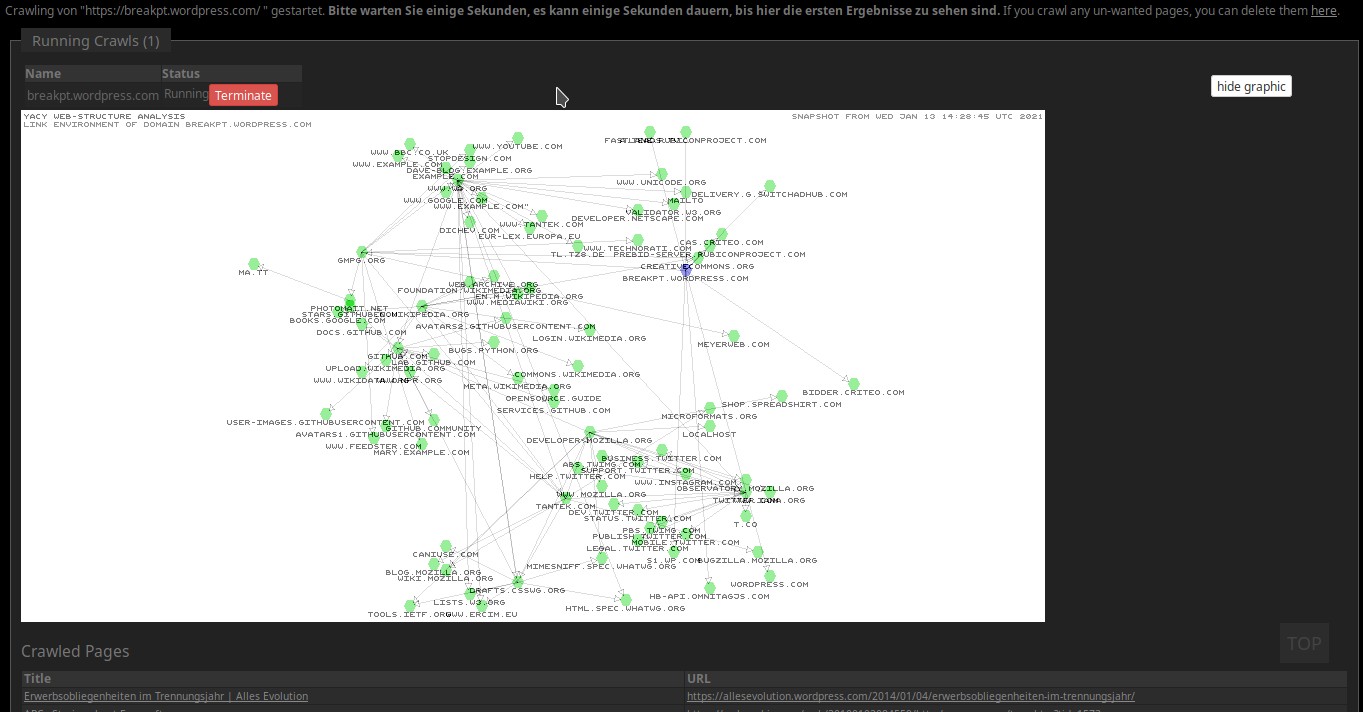
(rechts unten das „TOP“ kommt von meinem Browser, also nicht beachten)
Man könnte hier noch einiges einstellen, aber das ist nicht nötig und ich habe da auch nie etwas daran gemacht. Euer YaCy arbeitet also jetzt so vor sich hin, bis der Crawl fertig ist. Wobei ihr auf den Screenshots sehen könnt, daß man einen Crawl auch einfach beenden kann!
Dies war also die erste Möglichkeit, wie man den Index von YaCy befüllen kann. Es gibt jedoch eine weitere Möglichkeit, welche auch das System nicht so belastet:
Indexieren per RSS-Feed!
 Viele Blogs, Magazine, Foren u.s.w. bieten einen sogenannten RSS-Feed an, welchen man abonnieren kann, damit man automatisch über neue Beiträge benachrichtigt wird. Diese Möglichkeit finde ich deutlich besser wie das abonnieren per E-Mail, denn was gehen diese mir fremden Leute meine Daten an? Solch ein Feed hat zudem den Vorteil, daß man ihn auch für YaCy verwenden kann! Das wollen wir uns nun ansehen, denn das ist wirklich sehr praktisch.
Viele Blogs, Magazine, Foren u.s.w. bieten einen sogenannten RSS-Feed an, welchen man abonnieren kann, damit man automatisch über neue Beiträge benachrichtigt wird. Diese Möglichkeit finde ich deutlich besser wie das abonnieren per E-Mail, denn was gehen diese mir fremden Leute meine Daten an? Solch ein Feed hat zudem den Vorteil, daß man ihn auch für YaCy verwenden kann! Das wollen wir uns nun ansehen, denn das ist wirklich sehr praktisch.
Im oben gezeigten „Produktionsmenü“ wählen wir dazu den Punkt „Daten Export / Import“, dann erscheint folgendes Bild:
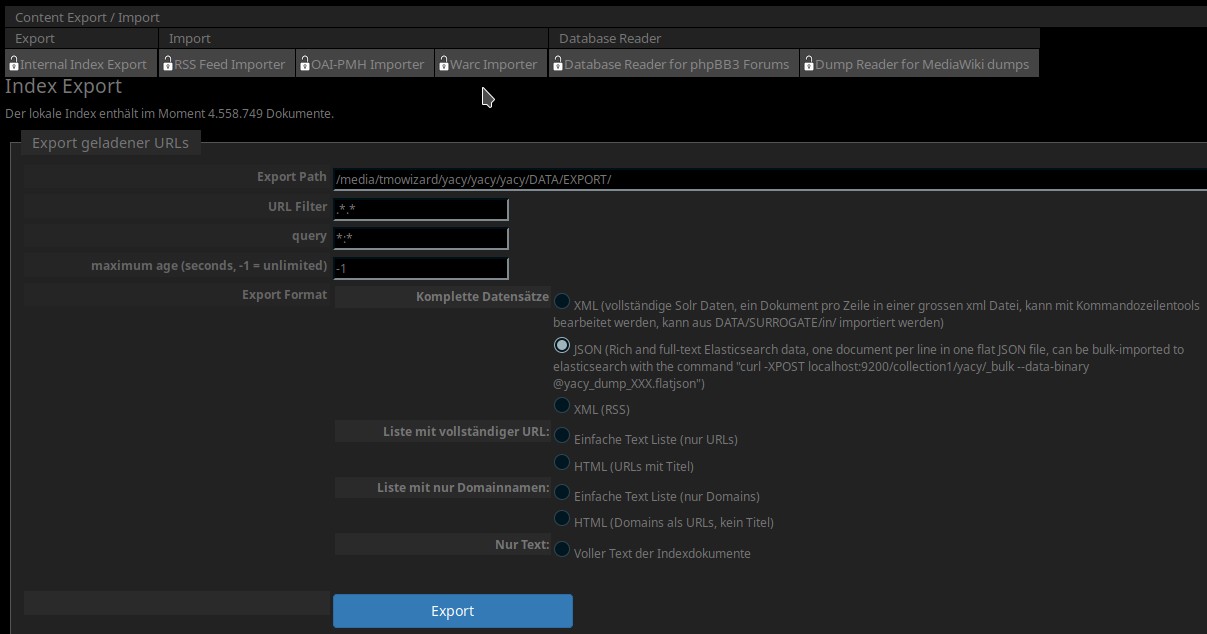
Man sieht dann oben im Menü bereits den entsprechenden Punkt „RSS Feed Importer“, welchen man nun auswählt:
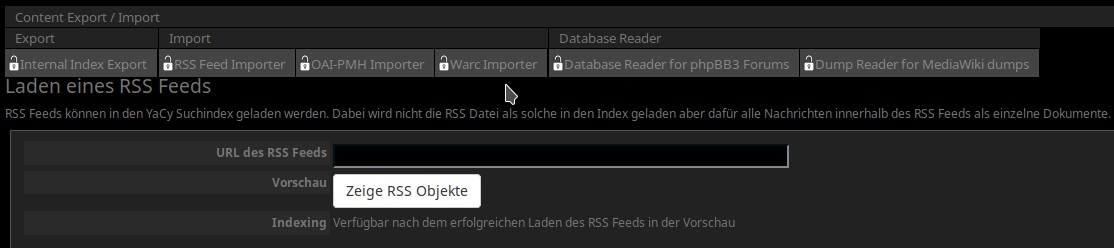
Viel einstellen kann man hier nicht, nämlich gar nichts! ;-) Man gibt einfach die Adresse des RSS-Feed an und drückt auf „Zeige RSS Objekte“, dann geschieht folgendes:
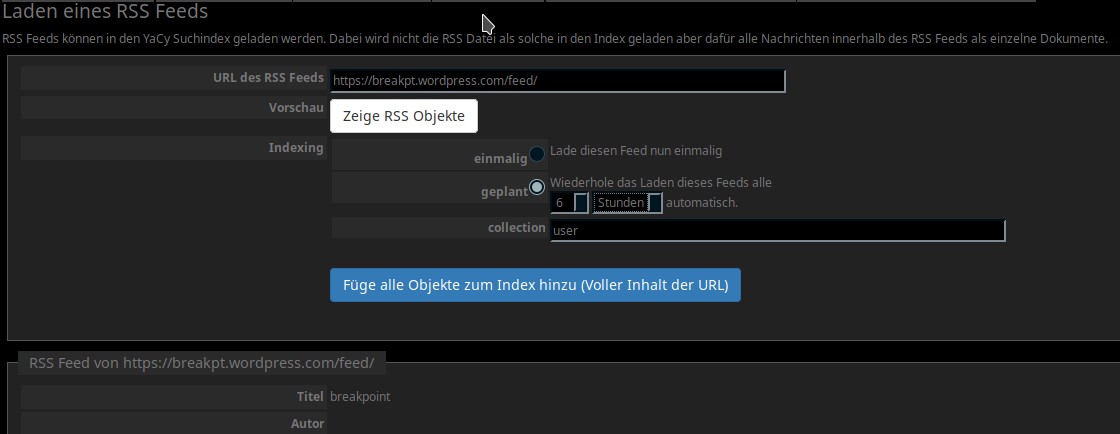
Hier könnt ihr z. B. angeben, wie oft ihr den Feed überprüfen wollt. Wie auch hier auf dem Blog gibt es natürlich auch auf anderen Webseiten immer mal was Neues, deswegen habe ich hier eine Wiederholung von 6 Stunden gewählt. Dann drückt man den Button darunter und das war es auch schon! YaCy prüft nun in meinem Fall alle 6 Stunden den Feed auf neue Artikel, so daß die Suchergebnisse immer relativ aktuell sind. Dabei wird auch euer System nicht so arg belastet wie mit einem normalen Crawl, gerade auf altersschwachen Geräten ist das ziemlich nützlich.
Diese Möglichkeit hat aber auch einen Fehler:
Leider haben selbst einige „große“ WordPress-Blogs ihre Feeds deaktiviert, eine völlig hirnlose Aktion! Das einzige Ergebnis dadurch ist, daß niemand mehr auf Neuigkeiten auf der Webseite aufmerksam gemacht wird: Keine Neuigkeiten, keine Besucher! Ich werde bestimmt keine Webseite auf Verdacht besuchen, Zitat Prof. Dr. Christian Drosten:
Ich habe Besseres zu tun!
Da schreibe ich dann doch lieber Tutorials für euch, da haben wenigstens mehr Leute was davon!
Keine Anonymität!
YaCy biete übrigens keine Anonymität im eigentlichen Sinn. Nur eure Suche ist Anonym, denn „Localhost“ oder die IP „127.0.0.1“ ist praktisch überall! Wenn ihr dann aber eine Website besucht, dann war es das auch schon. Da muß man dann schon einen entsprechenden Proxy oder VPN verwenden, YaCy ist dafür nicht gedacht.
Mein Fazit:
Ich habe euch hier zwei Möglichkeiten aufgezeigt, wie man den Index von YaCy vergrößern kann. Das normale Crawlen geht hierbei je nach Einstellung mehr in die Tiefe, belastet aber auch das eigene System ziemlich heftig. Dafür werden je nach Suchtiefe auch entsprechend viele verschiedene Websites in den Index aufgenommen, welche man eventuell gar nicht kennt.
Wenn man wie ich einen gut gefütterten Feed-Reader hat, dann lohnt sich aber auch die zweite Möglichkeit. Der Index wächst zwar am Anfang nicht besonders schnell, mit den von mir gezeigten Einstellungen (alle 6 Stunden aktuallisieren) dafür kontinuierlich.
Die einzige Grenze ist dabei die verwendete Festplatte, ich werde da wohl nicht mehr besonders weit kommen. Das ist auch ein Grund, warum ich für YaCy immer einen extra Rechner empfehle. YaCy fühlt sich dabei auch auf kleineren Rechnern wie bei mir wohl, gegen ein moderneres Gerät hätte YaCy aber bestimmt auch nichts einzuwenden! ;-) :mrgreen:
Die Suchergebnisse sind übrigens nicht wirklich sortiert, ihr findet dort also das was ihr wollt und nicht was euch irgend ein Tracker vorgibt! Dadurch habt ihr natürlich andere Ergebnisse wie z. B. bei Google oder bing, da diese ja mit entsprechenden Werbepartnern zusammen arbeiten. Bei Google werdet ihr je nach Suche kaum einen Blog wie mein Castle in der vordersten Reihe finden, da stehen normaler Weise Tageszeitungen und Magazine. Bei YaCy kann es euch jedoch passieren, daß ihr z. B. bei der Suche nach einem Tutorial ein euch völlig unbekanntes Blog mit deutlich einfacherer Schreibweise findet.
Wie schon mehrmals auf meinem Blog erwähnt gilt für YaCy kein LSR und auch kein „Recht auf Vergessen“, YaCy ist nicht zensierbar! Es gibt jedoch die Möglichkeiten von Black- und Whitelists, so daß man bestimmte Websites blockieren kann. Da YaCy bzw. der Index davon weltweit verteilt ist und überall andere Gesetze gelten ist eine Einschränkung oder gar Zensierung gar nicht umfänglich möglich.
Leider ist der Index von YaCy wieder ziemlich geschrumpft, derzeit sind wohl nur noch knapp 1.500 Peers mit insgesamt ~2,5 Milliarden Dokumenten vorhanden! Die Suchergebnisse sind folglich schlechter geworden wie noch vor knapp 2 Jahren (5 Milliarden Dokumente).😱😭 Scheinbar wollen die meisten Leute überwacht und getrackt werden bis zum gehtnichtmehr. Aber dann schimpfen von wegen Google und „Datenkrake“, irgendwie paßt das meiner Meinung nach nicht zusammen.
Ein Problem ist hierbei auch, daß es kaum Werbung für YaCy gibt. Das ist mit ein Grund, warum ich so oft darüber schreibe und Tutorials wie dieses veröffentliche. Irgend jemand muß es ja machen und ich habe ja wirklich viel Zeit, also schreibe ich das hier einfach mal so. ;-) Anonym bin ich sowieso nicht unterwegs, folglich ist es auch egal.
In diesem Sinne wünsche ich euch nun einen schönen Abend
Viele Grüße nun aus dem Rechenzentrum von TmoWizard’s Castle zu Augusta Vindelicorum 
Mike, TmoWizard ![]()
![]() YaCy-Tutorial: Websites indexieren mit #YaCy von TmoWizard ist lizenziert unter Creative Commons Namensnennung-NichtKommerziell-Weitergabe unter gleichen Bedingungen 4.0 international.
YaCy-Tutorial: Websites indexieren mit #YaCy von TmoWizard ist lizenziert unter Creative Commons Namensnennung-NichtKommerziell-Weitergabe unter gleichen Bedingungen 4.0 international.
One Reply to “YaCy-Tutorial: Websites indexieren mit #YaCy”